Single-threaded algorithms are fine and intuitive. There’s an single execution flow running our program in the exact order we specified it. However, modern CPUs have multiple cores sharing the same memory space, meaning that many instructions can be executed in the same clock cycle. Having an single execution flow would be a wasteful use of the resources we have available. That’s where multithread applications come in: It allows the use of true parallelism.
K-Means Clustering
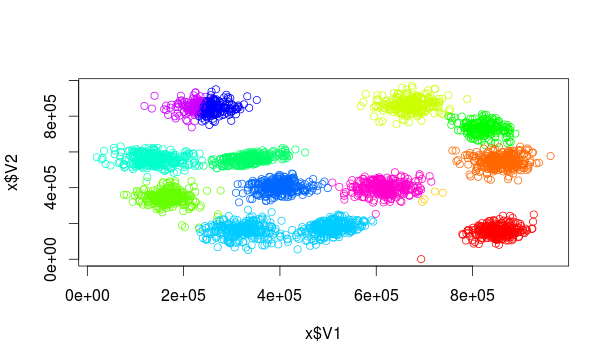
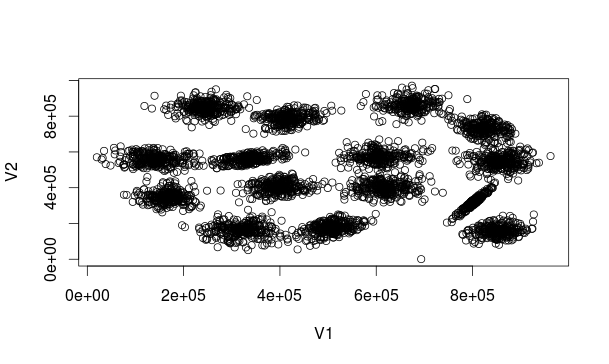
K-Means is a well-known clustering algorithm. Clustering is important in many areas: Machine learning, data mining, etc.,… Hence the importance of clustering algorithms. It’s success is due to two factors: Its simplicity and computational feasibility (running in O(nkdi), where n is the input size, k is the number of clusters, d is the input data dimension and i is the number of iterations needed to converge).
Knowing the number of clusters at priori (in the above case, 15), we want to know the center of mass of each cluster (the point on which the distance to all other points in the cluster is the minimal possible). In another words:
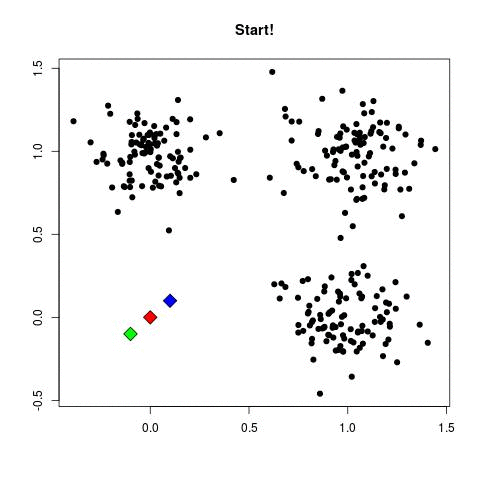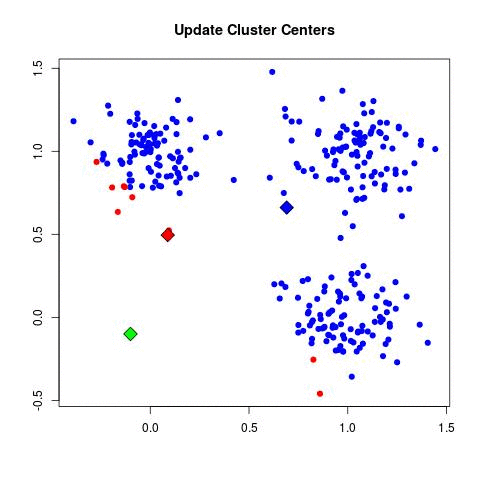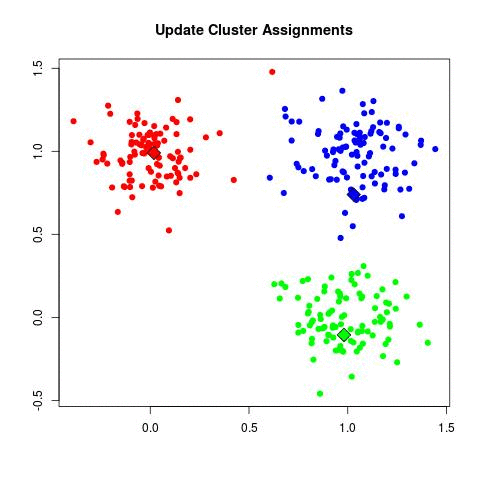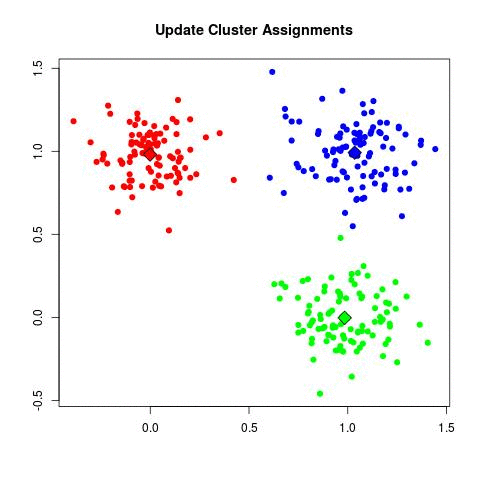
The intuition behind K-Means is as follows: First, assign k random centers. For each data in the dataset calculate the nearest random point and add it to the “cluster set” of the nearest center. Then, for each cluster set, calculate the mean point and use this mean point as a substitute to the random center. This process is done iteratively until the mean points remain unchanged between one iteration and another (it’s said that the algorithm “converged”). This gif explains the whole process nicely:
Before implementing this in Java, let’s write a simple pseudo-code:
1234567891011121314151617
Inputs:
- dataset: Set of N-dimensional points
- k: Number of clusters
Output:
- The center of mass of each cluster
KMEANS(dataset[], k):
centers[] = randomly_initialize_points(k)
converged = false
while not converged:
clusters = {}
for each data in dataset:
center, index = get_nearest_center(data, centers)
clusters[index].add(data)
new_centers[] = calculate_means(clusters)
converged = centers == new_centers
centers = new_centers
return centers
Take a grasp to ensure you have fully understood the above algorithm.
Java implementation
Our whole program will be contained inside a single class, KMeans.
KMeans.java
123
publicclassKMeans{}
Inside of it, let’s create a inner static class called Point2D, which will representate our data.
The method getDistance calculates the euclidean distance between two points. The method getNearestPointIndex returns the index of the nearest point in a list (it will be used to calculate the nearest center). Finally, getMean is a static method that receives a list of points and returns the mean point of that list (it will be used to calculate the new centers).
Let’s proceed now by creating a main to our main class:
The program expects two arguments: The path to the input file where the data is contained and the number of clusters (k). We read those arguments and set them to the variables inputFile and k.
The next thing we need to do is to read our data. Let’s do it now:
publicclassKMeans{privatestaticfinalintREPLICATION_FACTOR=200;...publicstaticList<Point2D>getDataset(StringinputFile)throwsException{List<Point2D>dataset=newArrayList<>();BufferedReaderbr=newBufferedReader(newFileReader(inputFile));Stringline;while((line=br.readLine())!=null){String[]tokens=line.split(",");floatx=Float.valueOf(tokens[0]);floaty=Float.valueOf(tokens[1]);Point2Dpoint=newPoint2D(x,y);for(inti=0;i<REPLICATION_FACTOR;i++)dataset.add(point);}br.close();returndataset;}publicstaticvoidmain(String[]args){...List<Point2D>dataset=null;try{dataset=getDataset(inputFile);}catch(Exceptione){System.err.println("ERROR: Could not read file "+inputFile);System.exit(-1);}}}
The method getDataset receives the path to the input file and returns a list of points. We read the file content using a BufferedReader and puts it into a variable called line. We then split that line by the “,” symbol (because the coordinates are comma separated), convert each token into a float and create a new Point2D instance from them, adding that instance to the list that will be returned. The only “awkward” thing is the existence of a for loop while adding the new point instance to the list. I added it to “replicate” the data (hence the REPLICATION_FACTOR variable), in order to observe the effects of parallelization more clearly.
OK! Now that we have the data, let’s randomly initialize the centers.
The kmeans method contains three parameters: centers (our randomly initialized centers), dataset (our set of point) and k (number of clusters) and returns a list of points (the final centers).
There’s a do/while loop which checks if the algorithm converged. Inside this loop, we get the new centers through the method getNewCenters, calculate the distance between the new centers and the old centers through the method getDistance and finally assign the old centers to the new centers. The algorithm will converge when the distance is equal to zero (the new centers are equal to the old centers).
Clear? Good, let’s start implementing the methods used inside the kmeans method, starting with getNewCenters:
Basically this is core of the K-Means algorithm. We first assign a list of lists called clusters, which is initialized with centers.size() empty lists. Then, for each data in our dataset, we get the nearest center index through the method getNearestPointIndex previously defined and append the data to the cluster list of the nearest center. Finally, on our third loop, for each cluster in clusters, we calculate the mean and append it to the newCenters variable, which we use as the return of our method.
Not very complicated, right? The getDistance method is easier:
publicclassKMeans{privatestaticfinalintREPLICATION_FACTOR=200;publicstaticclassPoint2D{privatefloatx;privatefloaty;publicPoint2D(floatx,floaty){this.x=x;this.y=y;}privatedoublegetDistance(Point2Dother){returnMath.sqrt(Math.pow(this.x-other.x,2)+Math.pow(this.y-other.y,2));}publicintgetNearestPointIndex(List<Point2D>points){intindex=-1;doubleminDist=Double.MAX_VALUE;for(inti=0;i<points.size();i++){doubledist=this.getDistance(points.get(i));if(dist<minDist){minDist=dist;index=i;}}returnindex;}publicstaticPoint2DgetMean(List<Point2D>points){floataccumX=0;floataccumY=0;if(points.size()==0)returnnewPoint2D(accumX,accumY);for(Point2Dpoint:points){accumX+=point.x;accumY+=point.y;}returnnewPoint2D(accumX/points.size(),accumY/points.size());}@OverridepublicStringtoString(){return"["+this.x+","+this.y+"]";}@Overridepublicbooleanequals(Objectobj){if(obj==null||!(obj.getClass()!=Point2D.class)){returnfalse;}Point2Dother=(Point2D)obj;returnthis.x==other.x&&this.y==other.y;}}publicstaticList<Point2D>getDataset(StringinputFile)throwsException{List<Point2D>dataset=newArrayList<>();BufferedReaderbr=newBufferedReader(newFileReader(inputFile));Stringline;while((line=br.readLine())!=null){String[]tokens=line.split(",");floatx=Float.valueOf(tokens[0]);floaty=Float.valueOf(tokens[1]);Point2Dpoint=newPoint2D(x,y);for(inti=0;i<REPLICATION_FACTOR;i++)dataset.add(point);}br.close();returndataset;}publicstaticList<Point2D>initializeRandomCenters(intn,intlowerBound,intupperBound){List<Point2D>centers=newArrayList<>(n);for(inti=0;i<n;i++){floatx=(float)(Math.random()*(upperBound-lowerBound)+lowerBound);floaty=(float)(Math.random()*(upperBound-lowerBound)+lowerBound);Point2Dpoint=newPoint2D(x,y);centers.add(point);}returncenters;}publicstaticList<Point2D>getNewCenters(List<Point2D>dataset,List<Point2D>centers){List<List<Point2D>>clusters=newArrayList<>(centers.size());for(inti=0;i<centers.size();i++){clusters.add(newArrayList<Point2D>());}for(Point2Ddata:dataset){intindex=data.getNearestPointIndex(centers);clusters.get(index).add(data);}List<Point2D>newCenters=newArrayList<>(centers.size());for(List<Point2D>cluster:clusters){newCenters.add(Point2D.getMean(cluster));}returnnewCenters;}publicstaticdoublegetDistance(List<Point2D>oldCenters,List<Point2D>newCenters){doubleaccumDist=0;for(inti=0;i<oldCenters.size();i++){doubledist=oldCenters.get(i).getDistance(newCenters.get(i));accumDist+=dist;}returnaccumDist;}publicstaticList<Point2D>kmeans(List<Point2D>centers,List<Point2D>dataset,intk){booleanconverged;do{List<Point2D>newCenters=getNewCenters(dataset,centers);doubledist=getDistance(centers,newCenters);centers=newCenters;converged=dist==0;}while(!converged);returncenters;}publicstaticvoidmain(String[]args){if(args.length!=2){System.err.println("Usage: KMeans <INPUT_FILE> <K>");System.exit(-1);}StringinputFile=args[0];intk=Integer.valueOf(args[1]);List<Point2D>dataset=null;try{dataset=getDataset(inputFile);}catch(Exceptione){System.err.println("ERROR: Could not read file "+inputFile);System.exit(-1);}List<Point2D>centers=initializeRandomCenters(k,0,1000000);longstart=System.currentTimeMillis();kmeans(centers,dataset,k);System.out.println("Time elapsed: "+(System.currentTimeMillis()-start)+"ms");System.exit(0);}}
Parallelization analysis
Now that we have implemented our K-Means algorithm, it’s time to decide what can be parallelized and what cannot be.
Our main method is basically composed by three procedures:
Read data
Initialize centers
Call kmeans method
The first one cannot be parallelized, the second is too simple. Now let’s take a further look at the kmeans method.
We cannot parallelize the loop due to the fact that a iteration depends on the result of the previous iteration. Let’s check the loop body then.
The loop body is composed by two method calls:
Calculate new centers
Calculate distance between old and new centers
The second is too computationally inexpensive (assuming that k is low). Let’s take a further look at the first one.
The getNewCenters is composed by three loops:
Initialize clusters
Calculate the nearest center for each point in the dataset
Calculate the mean for each cluster
The first and third ones are too computationally inexpensive (assuming that k is low). However, the second one is expected to be the most computationally expensive part of our whole program, since it iterates over our data (O(kn)). And since the calculation for the nearest center can be done independently for each point in the dataset, it can be parallelized.
Implementing parallelization
The basic unit of parallelization in Java is a thread. A thread is a execution flow. Since our program is running inside the Java Virtual Machine, there’s no guarantee that each thread will be allocated to a different core, if available. However, the JVM does try, so it’s our best guess.
In order to parallelize the nearest center calculation loop, we first need to define the number of threads, partition our data by the number of threads, start each thread and wait for their terminations.
First, let’s create a method called concurrentKmeans which calls concurrentGetNewCenters:
This is pretty straight-forward, so let’s proceed. Now let’s define the number of threads and instanciate them inside the concurrentGetNewCenters method.
We defined a constant called NUM_THREADS initialized with an arbitrary value. We then partition our data, create an array of threads and in a loop loop we call the method createWorker which returns a new thread, which is started just after it. Finally, we call the method join in order to wait the worker threads termination.
What createWorker should be? Well, initially it can contain the same code we had in the loop body of the non-parallelized code.
While this may seem fine in theory, this program contains a serious problem called race conditions, due to the fact that the clusters variable is being modified by many threads at the same time. This obviously will lead to problems, so we need to restrict the access to the clusters variable to only one thread at once. In Java, this is done through the keyword synchronized (in more technical therms, synchronized creates a monitor. A monitor is a high-level abstration for a semaphore, particularly one with capacity equal to one, also called mutex, that allows only one execution flow to access the resource being synchronized at once).
Although the race conditions problem was solved, now our program has a performance issue. Why? Because the synchronized is killing all the parallelization! It’s forcing only one thread to execute the loop at once. We can solve this problem by breaking our method into two parts, once to calculate the nearest center and another to save the calculation into the clusters variable. Only the second one must be synchronized, and since it’s super fast, it won’t kill our parallelization.
There’s just one last thing that need to be fixed in order of our program to become optimal. Suppose we just have 4 cores, but we are creating 30 threads. Even if we manage to successfully allocate each thread to a different core, there are more threads than cores available. In another words, there will be an overhead that can hurt the performance of our program (besides unnecessary memory allocation). We could adjust the number of threads to the number of cores, but let’s go to the other way around: Let’s make our program only execute a limited number of threads at once. This can be done through the ExecutorService.
The first thing we need to do is to create a new ExecutorService informing the number of threads we want to execute at once. This can be done through the factory method newFixedThreadPool:
The Runtime method availableProcessors() returns the number of cores available. OK! Now we can call the ExecutorService invokeAll method, which add all threads to the thread pool and blocks the current thread until all workers threads have been finished. Very convenient, right? The invokeAll method expects to receive a list of callables, so let’s modify our workerThread method to return a Callable instead of a Thread:
That’s it! Our parallelized version is done! Yay! :D
Results
Running our program, we can observe a speedup of 50% of the parallelized version in relation to the non-parallelized version, depending on the number of cores of your CPU.
importjava.io.BufferedReader;importjava.io.FileReader;importjava.util.ArrayList;importjava.util.List;importjava.util.concurrent.Callable;importjava.util.concurrent.ExecutorService;importjava.util.concurrent.Executors;publicclassKMeans{privatestaticfinalintREPLICATION_FACTOR=200;privatestaticfinalintNUM_THREADS=30;publicstaticclassPoint2D{privatefloatx;privatefloaty;publicPoint2D(floatx,floaty){this.x=x;this.y=y;}privatedoublegetDistance(Point2Dother){returnMath.sqrt(Math.pow(this.x-other.x,2)+Math.pow(this.y-other.y,2));}publicintgetNearestPointIndex(List<Point2D>points){intindex=-1;doubleminDist=Double.MAX_VALUE;for(inti=0;i<points.size();i++){doubledist=this.getDistance(points.get(i));if(dist<minDist){minDist=dist;index=i;}}returnindex;}publicstaticPoint2DgetMean(List<Point2D>points){floataccumX=0;floataccumY=0;if(points.size()==0)returnnewPoint2D(accumX,accumY);for(Point2Dpoint:points){accumX+=point.x;accumY+=point.y;}returnnewPoint2D(accumX/points.size(),accumY/points.size());}@OverridepublicStringtoString(){return"["+this.x+","+this.y+"]";}@Overridepublicbooleanequals(Objectobj){if(obj==null||!(obj.getClass()!=Point2D.class)){returnfalse;}Point2Dother=(Point2D)obj;returnthis.x==other.x&&this.y==other.y;}}publicstaticList<Point2D>getDataset(StringinputFile)throwsException{List<Point2D>dataset=newArrayList<>();BufferedReaderbr=newBufferedReader(newFileReader(inputFile));Stringline;while((line=br.readLine())!=null){String[]tokens=line.split(",");floatx=Float.valueOf(tokens[0]);floaty=Float.valueOf(tokens[1]);Point2Dpoint=newPoint2D(x,y);for(inti=0;i<REPLICATION_FACTOR;i++)dataset.add(point);}br.close();returndataset;}publicstaticList<Point2D>initializeRandomCenters(intn,intlowerBound,intupperBound){List<Point2D>centers=newArrayList<>(n);for(inti=0;i<n;i++){floatx=(float)(Math.random()*(upperBound-lowerBound)+lowerBound);floaty=(float)(Math.random()*(upperBound-lowerBound)+lowerBound);Point2Dpoint=newPoint2D(x,y);centers.add(point);}returncenters;}privatestaticCallable<Void>createWorker(finalList<Point2D>partition,finalList<Point2D>centers,finalList<List<Point2D>>clusters){returnnewCallable<Void>(){@OverridepublicVoidcall()throwsException{intindexes[]=newint[partition.size()];for(inti=0;i<partition.size();i++){Point2Ddata=partition.get(i);intindex=data.getNearestPointIndex(centers);indexes[i]=index;}synchronized(clusters){for(inti=0;i<indexes.length;i++){clusters.get(indexes[i]).add(partition.get(i));}}returnnull;}};}privatestatic<V>List<List<V>>partition(List<V>list,intparts){List<List<V>>lists=newArrayList<List<V>>(parts);for(inti=0;i<parts;i++){lists.add(newArrayList<V>());}for(inti=0;i<list.size();i++){lists.get(i%parts).add(list.get(i));}returnlists;}publicstaticList<Point2D>concurrentGetNewCenters(finalList<Point2D>dataset,finalList<Point2D>centers){finalList<List<Point2D>>clusters=newArrayList<List<Point2D>>(centers.size());for(inti=0;i<centers.size();i++){clusters.add(newArrayList<Point2D>());}List<List<Point2D>>partitionedDataset=partition(dataset,NUM_THREADS);ExecutorServiceexecutor=Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());List<Callable<Void>>workers=newArrayList<>();for(inti=0;i<NUM_THREADS;i++){workers.add(createWorker(partitionedDataset.get(i),centers,clusters));}try{executor.invokeAll(workers);}catch(InterruptedExceptione){e.printStackTrace();System.exit(-1);}List<Point2D>newCenters=newArrayList<>(centers.size());for(List<Point2D>cluster:clusters){newCenters.add(Point2D.getMean(cluster));}returnnewCenters;}publicstaticList<Point2D>getNewCenters(List<Point2D>dataset,List<Point2D>centers){List<List<Point2D>>clusters=newArrayList<>(centers.size());for(inti=0;i<centers.size();i++){clusters.add(newArrayList<Point2D>());}for(Point2Ddata:dataset){intindex=data.getNearestPointIndex(centers);clusters.get(index).add(data);}List<Point2D>newCenters=newArrayList<>(centers.size());for(List<Point2D>cluster:clusters){newCenters.add(Point2D.getMean(cluster));}returnnewCenters;}publicstaticdoublegetDistance(List<Point2D>oldCenters,List<Point2D>newCenters){doubleaccumDist=0;for(inti=0;i<oldCenters.size();i++){doubledist=oldCenters.get(i).getDistance(newCenters.get(i));accumDist+=dist;}returnaccumDist;}publicstaticList<Point2D>kmeans(List<Point2D>centers,List<Point2D>dataset,intk){booleanconverged;do{List<Point2D>newCenters=getNewCenters(dataset,centers);doubledist=getDistance(centers,newCenters);centers=newCenters;converged=dist==0;}while(!converged);returncenters;}publicstaticList<Point2D>concurrentKmeans(List<Point2D>centers,List<Point2D>dataset,intk){booleanconverged;do{List<Point2D>newCenters=concurrentGetNewCenters(dataset,centers);doubledist=getDistance(centers,newCenters);centers=newCenters;converged=dist==0;}while(!converged);returncenters;}publicstaticvoidmain(String[]args){if(args.length!=2){System.err.println("Usage: KMeans <INPUT_FILE> <K>");System.exit(-1);}StringinputFile=args[0];intk=Integer.valueOf(args[1]);List<Point2D>dataset=null;try{dataset=getDataset(inputFile);}catch(Exceptione){System.err.println("ERROR: Could not read file "+inputFile);System.exit(-1);}List<Point2D>centers=initializeRandomCenters(k,0,1000000);System.out.println("Non-parallelized version");longstart=System.currentTimeMillis();kmeans(centers,dataset,k);System.out.println("Time elapsed: "+(System.currentTimeMillis()-start)+"ms");System.out.println("Parallelized version");start=System.currentTimeMillis();concurrentKmeans(centers,dataset,k);System.out.println("Time elapsed: "+(System.currentTimeMillis()-start)+"ms");System.exit(0);}}
Conclusion
In this tutorial, we learnt about K-Means clustering, threads, race conditions, monitors and thread pools (ExecutionService). Excellent! With the knowledge obtained in this tutorial, you already are able to do some basic concurrent programming in Java! :)